Postgres logical replication is a versatile mechanism for replicating data objects and their modifications. It differs from physical replication by focusing on transactional changes, based on object identity like primary keys, instead of byte-by-byte copying. This ensures changes on the subscriber maintain the same commit order as on the publisher, guaranteeing data consistency. Logical replication supports selective replication and works across different versions of Postgres.
This guide explains the inner workings of Postgres logical replication. It explores key processes and focuses on using the pg_subscription_rel system catalog for monitoring and troubleshooting.
Prerequisites
This guide assumes you have a basic understanding of Postgres logical replication concepts and have a working logical replication setup. If you need a refresher on logical replication basics, check out our Postgres logical replication concepts guide.
Understanding key processes in logical replication
Logical replication in Postgres relies on several components working together to replicate data changes accurately. Understanding these components is crucial for effective monitoring and troubleshooting. Here are the key processes involved in logical replication:
Logical decoding
Logical decoding is fundamental to logical replication. It extracts changes from the Write-Ahead Log (WAL) and presents them in a structured format.
This process interprets the WAL, which records all database changes, and transforms it into an application-specific format like streams of tuples or SQL statements. The walsender process on the publisher handles logical decoding. Decoder plugins interpret WAL entries and convert them into a logical replication stream for the subscriber. These plugins translate raw WAL data into meaningful database modifications.
The Apply worker process
The apply worker process is crucial for logical replication on the subscriber. It receives changes from the publisher and applies them to the subscriber database. Starting on the subscriber, it connects to the publisher and communicates with the walsender process. The apply worker receives a stream of decoded and filtered logical changes from the walsender. It then applies these changes to the correct tables in the subscriber database.
To maintain transactional consistency, the apply worker applies INSERT, UPDATE, DELETE, and TRUNCATE operations in the same commit order as on the publisher.
During subscription setup, the apply worker may start tablesync worker processes for initial table synchronization. The max_logical_replication_workers setting limits the total number of apply and tablesync workers.
The Tablesync worker process
The Tablesync worker process handles initial data synchronization when creating a new subscription. Started by the apply worker, it manages copying existing data. For each table in a new subscription, the apply worker starts a tablesync worker.
The tablesync worker uses the efficient COPY command to transfer all data from the publisher to the subscriber. After copying, it requests the publisher to replicate changes during the copy process, fully synchronizing the subscriber table. Multiple tablesync workers can run in parallel to speed up synchronization, especially with many tables. max_sync_workers_per_subscription controls parallelism for a single subscription.
Workflow of data changes in logical replication
Let's walk through the typical workflow of data changes in Postgres logical replication. This sequence illustrates how data modifications on the publisher propagate to the subscriber, ensuring consistent replication.
Process from data change on publisher to application on subscriber
-
Data modification on the publisher: A transaction on the publisher database modifies data in a published table. This can be
INSERT,UPDATE,DELETE, orTRUNCATE. -
Write-ahead log (WAL) generation: Postgres records every modification in the Write-Ahead Log (WAL) before applying changes to tables. Each change is a WAL record with a unique Log Sequence Number (LSN). This ensures data durability and crash recovery.
-
Logical decoding by the walsender:
- When a subscriber connects and a subscription is active, a walsender process starts on the publisher.
- The walsender reads the WAL from the replication slot's position for that subscriber.
- It uses the
pgoutputplugin (default) to transform raw WAL entries into a stream of logical changes:INSERT,UPDATE, orDELETEstatements. - The walsender filters these changes based on the publication definition, only considering modifications to subscribed tables.
-
Streaming of changes via the replication slot:
- The walsender transmits decoded, filtered changes to the subscriber through the replication slot.
- The replication slot on the publisher tracks replication progress, recording the LSN of the last sent change.
- LSN tracking ensures WAL segments are retained by the publisher, even if the subscriber is temporarily offline, until the subscriber confirms data reception.
-
Reception and application of changes by the apply worker:
- On the subscriber, the apply worker receives the stream of logical changes.
- The apply worker maps these operations to tables in the subscriber database.
- Critically, the apply worker applies changes in the exact commit order from the publisher, maintaining transactional consistency.
-
Initial data synchronization using tablesync workers:
- When a new subscription is created (and
copy_datais enabled, the default), the apply worker starts. - The apply worker then launches tablesync workers, typically one per table in the subscription.
- Each tablesync worker creates a replication slot on the publisher. This slot ensures a consistent snapshot of the table data.
- The tablesync worker uses the
COPYcommand to efficiently transfer the table's data to the subscriber. - After copying, the tablesync worker synchronizes. It consumes the replication stream from the walsender to catch up on changes that occurred during the data copy. This ensures the subscriber table is consistent with the publisher at the point of synchronization.
- Once synchronized, the tablesync worker finishes, and the apply worker handles ongoing replication.
- When a new subscription is created (and
This workflow ensures reliable and consistent replication of publisher data modifications to the subscriber, maintaining transactional integrity. Tablesync workers handle initial synchronization, and walsender and apply worker processes manage continuous, real-time replication of incremental changes.
Monitoring replication status with pg_subscription_rel
Now that we've covered the internal workings, let's focus on monitoring replication using pg_subscription_rel. This system catalog provides real-time insights into the replication status of tables within a subscription.
What is pg_subscription_rel?
pg_subscription_rel is a Postgres system catalog providing real-time status information for each table in a logical replication subscription. It's a detailed, table-specific dashboard for your replication setup.
Unlike catalogs with broader replication statistics, pg_subscription_rel shows the relationship between subscriptions and replicated tables. It offers a detailed view of which tables belong to which subscriptions and their current replication state.
Key columns in pg_subscription_rel
To use pg_subscription_rel for monitoring, understanding its key columns is essential:
-
srsubid(oid): A foreign key linking to thepg_subscriptioncatalog. It uniquely identifies the subscription for a table. Each row inpg_subscription_relis associated with a subscription. -
srrelid(oid): Another foreign key, linking topg_class. It identifies the specific table (relation) being replicated. This column shows which table's replication status is reported in that row. -
srsubstate(char): The most important column for monitoring. A single-character code indicating the current replication state of the table within the subscription. State codes are detailed in the next section. -
srsublsn(pg_lsn): It stores the Log Sequence Number (LSN) from the publisher, associated with the most recent state change for the table. LSNs track replication progress and ensure data consistency. This value is meaningful in 'synchronized' or 'ready' states, reflecting the subscriber's progress in the publisher's transaction log.
Understanding the srsubstate codes
The srsubstate column uses single-character codes for different stages in a table's replication lifecycle. These sequential states clearly show replication progress for each table. Here’s a breakdown of each code:
-
i- Initialize: A table enters "Initialize" when added to a subscription. The subscription is aware of the table and preparing for replication. No data synchronization or active replication has started yet. -
d- Data is being copied: It means initial data synchronization is active. Atablesync workeris copying table data from publisher to subscriber usingCOPY. -
f- Finished table copy: This state confirms thetablesync workercompleted the initial data copy. However, the table might not be fully synchronized yet, as changes could have occurred on the publisher during the copy. -
s- Synchronized: This state is a crucial intermediary state. The subscriber has caught up with all publisher changes committed up to the point of initial data copy. The subscriber's table reflects a consistent snapshot of the publisher's table, including transactions during the copy. -
r- Ready (Normal replication): This is the desired, stable state in LR, the table is actively and continuously replicating changes from the publisher. Theapply workerreceives and applies these changes to the subscriber ongoing.
The typical lifecycle and transitions of these states are visualized in the diagram below:
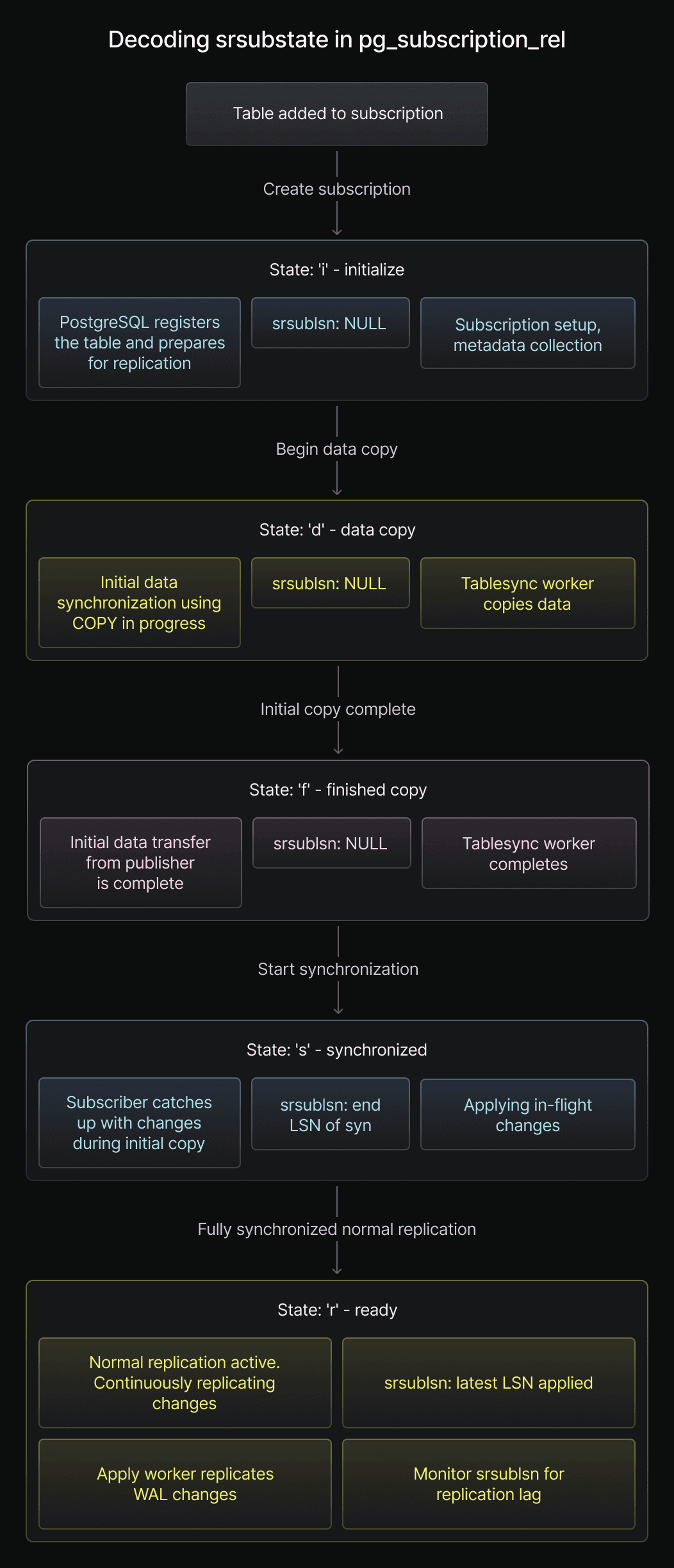
Typical state progression:
| State code | Description |
|---|---|
i | Table added to subscription. |
d | Initial data copy in progress. |
f | Data copy complete. |
s | Table synchronized with publisher. |
r | Normal replication active. |
States progress sequentially from 'i' to 'r' (i -> d -> f -> s -> r), with 'r' (Ready) being the desired state for normal ongoing replication.
Understanding state progression is key to interpreting replication status and quickly identifying issues. Unexpected or prolonged states can signal potential problems in the replication setup. We'll delve into troubleshooting based on these states later in the guide.
Still Confused between 's' and 'r' states?
It's easy to confuse 's' (Synchronized) and 'r' (Ready) states. Here's a simple distinction:
The 's' (Synchronized) state is transitional. It means the initial data copy is complete, and the subscriber has caught up to a specific point in time on the publisher. It's the end of the initial catch-up phase.
The 'r' (Ready) state indicates full, continuous replication mode. Changes stream from the publisher and are applied to the subscriber in real-time, going forward. In 'r' state, srsublsn updates continuously, reflecting the stream of latest changes.
Monitoring replication status using SQL queries
To check the replication state of tables within a specific subscription, execute the following SQL query on the subscriber database:
SELECT srrelid::regclass, srsubstate
FROM pg_subscription_rel
WHERE srsubid = 'your_subscription_oid'::oid;Before running this query, you need to replace 'your_subscription_oid' with the actual Object Identifier (OID) of your subscription. You can find your subscription's OID by querying the pg_subscription system catalog. For example:
SELECT oid, subname FROM pg_subscription;This query returns the OID and name of all subscriptions in the database. Use the OID of the subscription you want to monitor in the pg_subscription_rel query.
Troubleshooting logical replication issues
Once you have successfully monitored the replication status using pg_subscription_rel, you can use the information to troubleshoot common logical replication issues
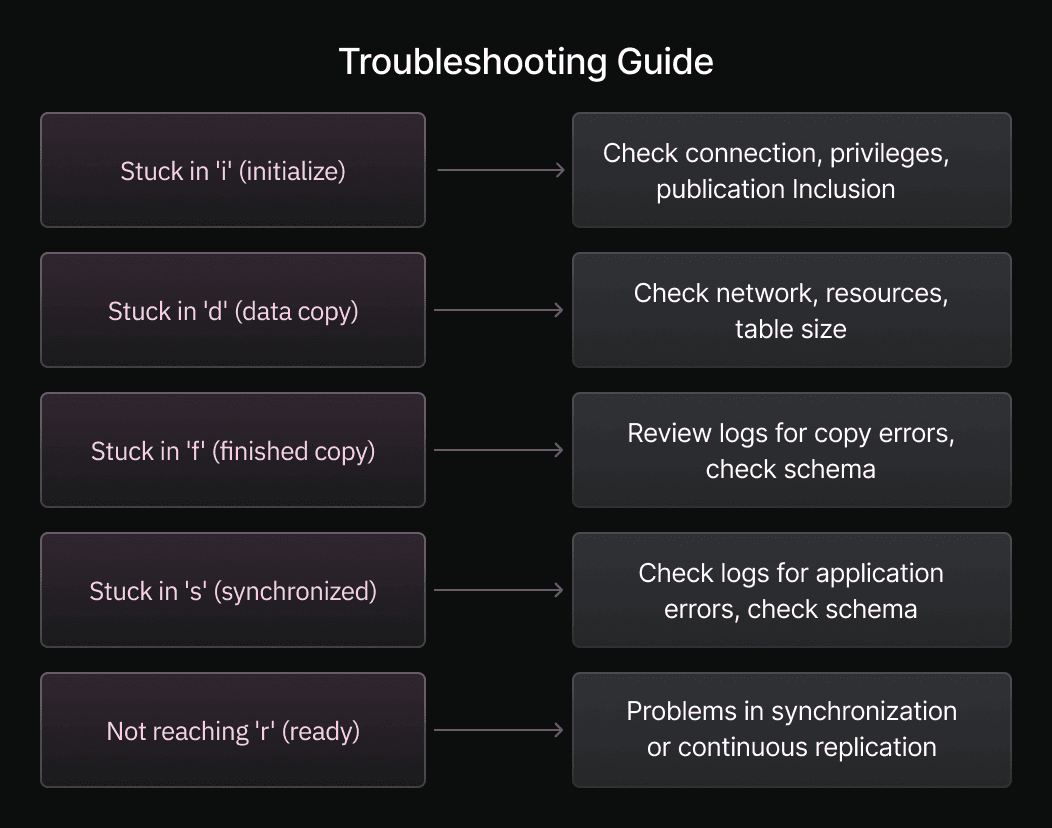
Troubleshooting steps Based on srsubstate:
-
Table stuck in 'i' (initialize) state:
- Check publisher connection details: Verify connection details (hostname, port, credentials) to the publisher are correct in the subscription definition.
- Verify replication privileges: Ensure the subscription user has necessary replication privileges on the publisher database to connect and stream changes.
- Examine publication inclusion: On the publisher, verify the table is correctly included in the publication the subscription uses. Forgetting to add tables to publications is common.
-
Table stuck in 'd' (data copy) state:
- Investigate network connectivity: Check network connection between subscriber and publisher. Look for latency or instability slowing down data copy.
- Monitor resource utilization: Check CPU, memory, disk I/O on both subscriber and publisher. Resource bottlenecks prolong data copy.
- Assess table size: Large tables take longer to copy. A prolonged 'd' state may be normal for very large tables.
-
Table stuck in 'f' (finished copy) state:
- Review subscriber logs for copy errors: Examine subscriber Postgres logs for errors during or after data copy. Logs may detail why the process isn't proceeding beyond 'f'.
- Check schema compatibility: Carefully verify schema compatibility between publisher and subscriber tables. Data type, constraint, or column definition differences can cause issues after data copy, preventing transition to 'synchronized'.
-
's' state: Expected during initial setup, indicating synchronization and expected transition to 'r'.
-
'r' state: Normal, healthy state. Ongoing replication is active. It is the desired state for continuous replication.
In addition to monitoring the pg_subscription_rel catalog and its states, it is also essential to monitor the overall resource utilization on both the publisher and subscriber. This includes monitoring disk space usage (especially on the publisher for WAL retention), CPU utilization, and memory consumption. High resource usage can often indicate performance bottlenecks in the replication process which need to be addressed.